
How AI is becoming both more and less open
Two things are equally true when we think about AI:
1 – We’re using it all the time
2 – It’s using us even more
The latest AI company to come under fire for illegally scraping data to train its models is video generator Runway. The startup, which is backed by Google and Nvidia, has been trained on thousands of YouTube videos and pirated movies — they even recorded it all in a spreadsheet.
It’s the latest in a long line of illicit AI training and scraping cases, like the Forbes lawsuit against Perplexity AI. And according to new research in “Consent in Crisis: The Rapid Decline of the AI Data Commons”, companies have started to take a stand.
5% of websites have added or modified their robots.txt file to block AI scrapers. When we filter out the most inactive or un-maintained websites, it’s actually 28%. And these numbers only account for full blocks, not partial restrictions, and only those that can be seen in terms of service agreements, too.
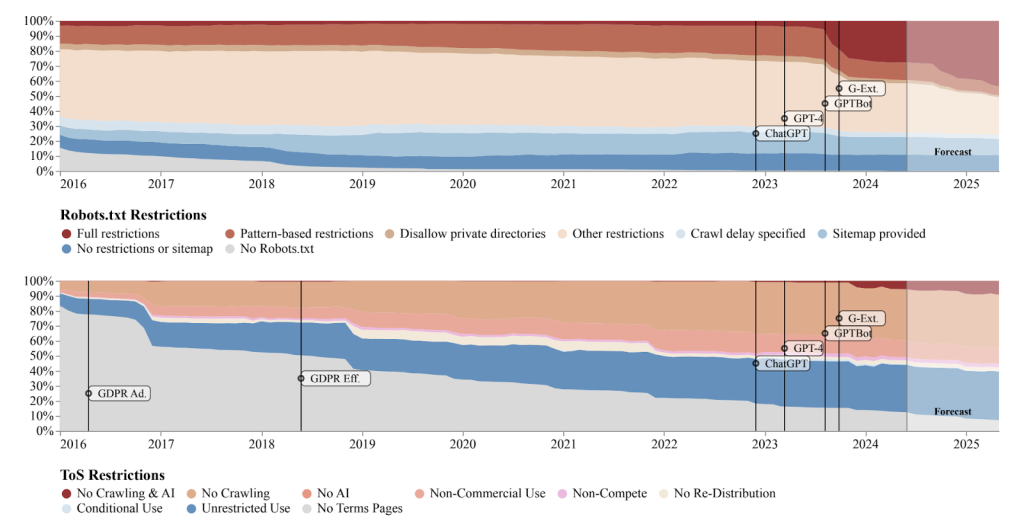
This tells us two things: that the data AI models are trained on is drying up, and that people are getting tired of their data being scraped.
For AI companies, there are a couple of solutions to a drop in free data — aside from skirting the law.
Synthetic data is a big one — data that is computer-generated, increasingly by generative AI. It’s a quick, inexpensive alternative to real data that also combats privacy concerns because it isn’t based on actual people. But experts are divided on how useful this alternative can truly be long-term.
One recent study by The New York Times shows how synthetic data degrades over time.

Another option for AI companies is to license data from media outlets and other sources. Many big names have signed on to allow OpenAI to use its data, including the Associated Press, the Atlantic, Vox Media, Axel Springer (Business Insider, Politico), the Financial Times, and Condé Nast (Vogue, GQ, Wired, Ars Technica, Vanity Fair, the New Yorker). Other companies have signed similar agreements with Google like News Corp (Wall Street Journal, the New York Post).
However, many other media companies have rejected these deals. Some, including the New York Times and several major record labels, are even currently involved in lawsuits against OpenAI and other AI companies.
Unfortunately, a drop in free data also discourages open-source and non-commercial (ie research) models. For now, we’re seeing an increase in open-source models, but the big names remain closed and there’s limited challenge to their dominance.
There’s another way that AI might be getting more open, too.
The US is considering an exemption that makes “good-faith” AI jailbreaking legal. Exemptions currently exist for hacking devices like phones & (believe it or not) tractors for repair purposes and for security researchers.
A lot of what we know about how big models like ChatGPT work is thanks to researchers and journalists trying to jailbreak the AI. They’re often trying to test if a model has been trained on copyrighted material & how it reaches its conclusions. Currently, OpenAI and other large models prohibit this in their terms of service.

For example, several major record labels input copyrighted material — lyrics that they own — into music generative AIs Udio and Suno. From the lyrics and other prompts, the AIs reproduced the songs’ (copyrighted) compositions, proving they had been trained on the material
But because the researchers input copyrighted material into the AI models, they were technically breaking the terms of service — even though the copyrighted material was their own, and they were using it to expose illegal activity.
The exemption has the support of the Department of Justice. (Actually, the DoJ says existing security-related exemptions should apply to AI, but that the Copyright Office should clarify if this is the case). Other supporters include the Hacking Policy Council, OpenPolicy & HackerOne.
So what does all this mean? We’re at a fork in the road with AI — and we’re currently trying to go both ways. The future of AI is being shaped right now, not just by policymakers but by all of us.
Will we choose to make it more or less open?










8899winlogin has the best rates out of everywhere I check! Check them out now! at 8899winlogin.
Been messing around on 585bet2 lately. Nothing crazy, but it’s a good way to kill some time. Site’s easy to navigate, which is something I appreciate. Give it a spin 585bet2.
Yo! Giving lucky100game a shot. Pretty fun little site. Easy to navigate and some decent slots. Worth a look: lucky100game